2. Trabajando con data
Conoceremos las estructuras de datos de fundamental importancia en Python: tuples, lists, sets y dictionaries. Presentaremos algunos patrones comunes para el manejo de datos y discutiremos el modelo de objetos en Python.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.1 Tipos y estructuras de data
Esta sección presenta estructuras de datos en forma de tuplas y diccionarios.
2.1.1 Tipos primitivos
Python tiene algunos tipos primitivos de datos:
- Enteros
- Números de punto flotante
- Cadenas (texto)
Aprendimos sobre esto en la introducción.
2.1.2 Tipo None
email_address = None
None se utiliza a menudo como marcador de posición para un valor opcional o faltante. Eso se evalúa como "Falso" en condicionales.
if email_address:
send_email(email_address, msg)
2.1.3: Estructuras de data
Los programas reales tienen datos más complejos. Por ejemplo, información sobre una participación en acciones:
100 acciones de GOOG a $490.10
Este es un "objeto" con tres partes:
- Nombre o símbolo de la acción ("GOOG", una cadena)
- Número de acciones (100, un número entero)
- Precio (490,10 un punto flotante)
2.1.4: Tuplas
Una tupla es una colección de valores agrupados.
Ejemplo:
s = ('GOOG', 100, 490.1)
A veces el () es omitido.
s = 'GOOG', 100, 490.1'
Casos especiales (0-tupla, 1-tupla).
t = () # Una tupla vacía
w = ('GOOG', ) # Una tupla de 1-item
Las tuplas se utilizan a menudo para representar registros o estructuras simples. Normalmente, es un único objeto de varias partes.
Una buena analogía: Una tupla es como una sola fila en una tabla de base de datos.
El contenido de la tupla está ordenado (como una matriz).
s = ('GOOG', 100, 490.1)
name = s[0] # 'GOOG'
shares = s[1] # 100
price = s[2] # 490.1
Sin embargo, el contenido no se puede modificar.
>>> s[1] = 75
TypeError: object does not support item assignment
Sin embargo, puede crear una nueva tupla basada en una tupla actual.
s = (s[0], 75, s[2])
Las tuplas tienen más que ver con empaquetar elementos relacionados en una sola entidad, que con cualquier otra cosa.
s = ('GOOG', 100, 490.1)
Por tanto, la tupla es fácil de pasar a otras partes de un programa como un solo objeto.
2.1.5: Desempaque de Tuplas
Para usar la tupla en otro lugar, puede desempaquetar sus partes en variables.
name, shares, price = s
print('Cost', shares * price)
The number of variables on the left must match the tuple structure.
name, shares = s # ERROR
Traceback (most recent call last):
...
ValueError: too many values to unpack
2.1.6 Tuplas vs Listas
Tuples look like read-only lists. However, tuples are most often used for a single item consisting of multiple parts. Lists are usually a collection of distinct items, usually all of the same type.
record = ('GOOG', 100, 490.1) # Una tupla que representa un registro en una cartera
symbols = [ 'GOOG', 'AAPL', 'IBM' ] # Una lista que representa tres símbolos de acciones
2.1.7 Diccionarios
Un diccionario es la asignación de claves a valores. A veces también se le llama una tabla hash o matriz asociativa. Las claves sirven como índices para acceder a los valores.
s = {
'name': 'GOOG',
'shares': 100,
'price': 490.1
}
2.1.8 Operaciones comunes
To get values from a dictionary use the key names.
>>> print(s['name'], s['shares'])
GOOG 100
>>> s['price']
490.10
>>>
Para agregar o modificar valores, asigne usando los nombres de las claves.
>>> s['shares'] = 75
>>> s['date'] = '6/6/2007'
>>>
Para eliminar un valor, use la instrucción del.
>>> del s['date']
>>>
2.1.9 ¿Porqué diccionarios?
Los diccionarios son útiles cuando hay * muchos * valores diferentes y esos valores puede ser modificado o manipulado. Los diccionarios hacen que su código sea más legible.
s['price']
# vs
s[2]
2.1.10 Ejercicios
En los últimos ejercicios, escribió un programa que lee un archivo de datos Data/portfolio.csv.
Usando el módulo csv, es fácil leer el archivo fila por fila.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
>>> import csv
>>> f = open('Data/portfolio.csv')
>>> rows = csv.reader(f)
>>> next(rows)
['name', 'shares', 'price']
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>>
Aunque leer el archivo es fácil, a menudo querrá hacer más con el datos que leerlos. Por ejemplo, tal vez desee almacenarlo y comience a realizar algunos cálculos sobre él. Desafortunadamente, una "fila" sin procesar de datos no le da suficiente para trabajar. Por ejemplo, incluso un el cálculo matemático simple no funciona:
>>> row = ['AA', '100', '32.20']
>>> cost = row[1] * row[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't multiply sequence by non-int of type 'str'
>>>
Para hacer más, normalmente desea interpretar los datos sin procesar de alguna manera y convertirlo en un tipo de objeto más útil para que pueda trabajar con él más tarde. Dos opciones simples son tuplas o diccionarios.
Ejercicio 2.1: Tuplas
En el indicador interactivo, cree la siguiente tupla que represente la fila anterior, pero con las columnas numéricas convertidas a los números adecuados:
>>> t = (row[0], int(row[1]), float(row[2]))
>>> t
('AA', 100, 32.2)
>>>
Con esto, ahora puede calcular el costo total multiplicando las acciones y el precio:
>>> cost = t[1] * t[2]
>>> cost
3220.0000000000005
>>>
¿Las matemáticas están rotas en Python? ¿Cuál es el problema con la respuesta de 3220.0000000000005?
Este es un artefacto del hardware de punto flotante en su computadora que solo puede representar decimales con precisión en Base-2, no en Base-10. Incluso para cálculos simples que involucran decimales en base 10, se introducen pequeños errores. Esto es normal, aunque quizás un poco sorprendente si no lo ha visto antes.
Esto sucede en todos los lenguajes de programación que utilizan decimales de punto flotante, pero a menudo se oculta al imprimir. Por ejemplo:
>>> print(f'{cost:0.2f}')
3220.00
>>>
Las tuplas son de solo lectura. Verifique esto intentando cambiar el número de acciones a 75.
>>> t[1] = 75
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>>
Aunque no puede cambiar el contenido de la tupla, siempre puede crear una tupla completamente nueva que reemplace a la anterior.
>>> t = (t[0], 75, t[2])
>>> t
('AA', 75, 32.2)
>>>
Siempre que reasigne un nombre de variable existente como este, el valor anterior se descarta. Aunque la asignación anterior puede parecer que está modificando la tupla, en realidad está creando una nueva tupla y desechando la anterior.
Las tuplas se utilizan a menudo para empaquetar y descomprimir valores en variables. Intente lo siguiente:
>>> name, shares, price = t
>>> name
'AA'
>>> shares
75
>>> price
32.2
>>>
Tome las variables anteriores y vuelva a empaquetarlas en una tupla
>>> t = (name, 2*shares, price)
>>> t
('AA', 150, 32.2)
>>>
Ejercicio 2.2: Diccionarios como estructura de datos
Una alternativa a una tupla es crear un diccionario.
>>> d = {
'name' : row[0],
'shares' : int(row[1]),
'price' : float(row[2])
}
>>> d
{'name': 'AA', 'shares': 100, 'price': 32.2 }
>>>
Calcule el costo total de esta participación:
>>> cost = d['shares'] * d['price']
>>> cost
3220.0000000000005
>>>
Compare este ejemplo con el mismo cálculo que involucra tuplas anterior. Cambie el número de acciones a 75.
>>> d['shares'] = 75
>>> d
{'name': 'AA', 'shares': 75, 'price': 32.2 }
>>>
A diferencia de las tuplas, los diccionarios se pueden modificar libremente. Agrega algunos atributos:
>>> d['date'] = (6, 11, 2007)
>>> d['account'] = 12345
>>> d
{'name': 'AA', 'shares': 75, 'price':32.2, 'date': (6, 11, 2007), 'account': 12345}
>>>
Ejercicio 2.3: Otras operaciones adicionales
Si convierte un diccionario en una lista, obtendrá todas sus claves:
>>> list(d)
['name', 'shares', 'price', 'date', 'account']
>>>
De manera similar, si usa la fordeclaración para iterar en un diccionario, obtendrá las claves:
>>> for k in d:
print('k =', k)
k = name
k = shares
k = price
k = date
k = account
>>>
Pruebe esta variante que realiza una búsqueda al mismo tiempo:
>>> for k in d:
print(k, '=', d[k])
name = AA
shares = 75
price = 32.2
date = (6, 11, 2007)
account = 12345
>>>
También puede obtener todas las claves utilizando el método keys():
>>> keys = d.keys()
>>> keys
dict_keys(['name', 'shares', 'price', 'date', 'account'])
>>>
keys()es un poco inusual porque devuelve un dict_keysobjeto especial .
Se trata de una superposición del diccionario original que siempre le proporciona las claves actuales, incluso si el diccionario cambia. Por ejemplo, intente esto:
>>> del d['account']
>>> keys
dict_keys(['name', 'shares', 'price', 'date'])
>>>
Observe cuidadosamente que 'account'desapareció keysaunque no volvió a llamar d.keys().
Una forma más elegante de trabajar con claves y valores juntos es utilizar el items()método. Esto te da (key, value)tuplas:
>>> items = d.items()
>>> items
dict_items([('name', 'AA'), ('shares', 75), ('price', 32.2), ('date', (6, 11, 2007))])
>>> for k, v in d.items():
print(k, '=', v)
name = AA
shares = 75
price = 32.2
date = (6, 11, 2007)
>>>
Si tiene tuplas como items, puede crear un diccionario usando la dict()función. Intentalo:
>>> items
dict_items([('name', 'AA'), ('shares', 75), ('price', 32.2), ('date', (6, 11, 2007))])
>>> d = dict(items)
>>> d
{'name': 'AA', 'shares': 75, 'price':32.2, 'date': (6, 11, 2007)}
>>>
2.2 Contenedores
2.2.1: Visión General
Los programas a menudo tienen que trabajar con muchos objetos.
- Una cartera de acciones
- Una tabla de precios de acciones
Hay tres opciones principales para usar.
- Listas. Datos ordenados.
- Diccionarios. Datos desordenados.
- Conjuntos. Colección desordenada de artículos únicos.*
2.2.2: Listas como un Contenedor
Utilice una lista cuando sea importante el orden de los datos. Recuerde que las listas pueden contener cualquier tipo de objeto. Por ejemplo, una lista de tuplas.
portfolio = [
('GOOG', 100, 490.1),
('IBM', 50, 91.3),
('CAT', 150, 83.44)
]
portfolio[0] # ('GOOG', 100, 490.1)
portfolio[2] # ('CAT', 150, 83.44)
2.2.3: Construcción de una lista
Construyendo una lista desde cero.
records = [] # lista inicial
# Use .append() para agregar mas items
records.append(('GOOG', 100, 490.10))
records.append(('IBM', 50, 91.3))
...
Un ejemplo al leer registros de un archivo.
records = [] # lista inicial
with open('Data/portfolio.csv', 'rt') as f:
next(f) # Nos saltamos el encabezado
for line in f:
row = line.split(',')
records.append((row[0], int(row[1]), float(row[2])))
2.2.4: Diccionarios como contenedores
Los diccionarios son útiles si desea búsquedas aleatorias rápidas (por nombre de clave). Por ejemplo, un diccionario de precios de acciones:
prices = {
'GOOG': 513.25,
'CAT': 87.22,
'IBM': 93.37,
'MSFT': 44.12
}
Aquí hay algunas búsquedas simples:
>>> prices['IBM']
93.37
>>> prices['GOOG']
513.25
>>>
2.2.5: Construcción de un diccionario
Ejemplo de construcción de un dictado desde cero.
prices = {} # Initial empty dict
# Insert new items prices['GOOG'] = 513.25
prices['CAT'] = 87.22
prices['IBM'] = 93.37
Un ejemplo que completa el dict a partir del contenido de un archivo.
prices = {} # Initial empty dict
with open('Data/prices.csv', 'rt') as f:
for line in f:
row = line.split(',')
prices[row[0]] = float(row[1])
Nota: Si prueba esto en el Data/prices.csvarchivo, encontrará que casi funciona; hay una línea en blanco al final que hace que se bloquee. Necesitará encontrar alguna forma de modificar el código para tener en cuenta eso (vea el ejercicio 2.6).
2.2.6: Búsquedas de diccionario
Puede probar la existencia de una clave.
if key in d:
# YES else:
# NO
Puede buscar un valor que podría no existir y proporcionar un valor predeterminado en caso de que no exista.
name = d.get(key, default)
Un ejemplo:
>>> prices.get('IBM', 0.0)
93.37
>>> prices.get('SCOX', 0.0)
0.0
>>>
2.2.7: Claves compuestas
Casi cualquier tipo de valor se puede utilizar como clave de diccionario en Python. Una clave de diccionario debe ser de un tipo que sea inmutable. Por ejemplo, tuplas:
holidays = {
(1, 1) : 'New Years',
(3, 14) : 'Pi day',
(9, 13) : "Programmer's day",
}
Luego para acceder:
>>> holidays[3, 14]
'Pi day'
>>>
Ni una lista, un conjunto ni otro diccionario pueden servir como clave de diccionario, porque las listas y los diccionarios son mutables.
2.2.8: Conjuntos (Sets)
Los conjuntos son una colección de elementos únicos desordenados.
tech_stocks = { 'IBM','AAPL','MSFT' }
# alternativamente: tech_stocks = set(['IBM', 'AAPL', 'MSFT'])
Los conjuntos son útiles para las pruebas de pertenencia.
>>> tech_stocks
set(['AAPL', 'IBM', 'MSFT'])
>>> 'IBM' in tech_stocks
True
>>> 'FB' in tech_stocks
False
>>>
Los conjuntos también son útiles para la eliminación de duplicados.
names = ['IBM', 'AAPL', 'GOOG', 'IBM', 'GOOG', 'YHOO']
unique = set(names)
# unique = set(['IBM', 'AAPL','GOOG','YHOO'])
Operaciones de conjuntos adicionales:
names.add('CAT') # Add an item
names.remove('YHOO') # Remove an item
s1 | s2 # Set union
s1 & s2 # Set intersection
s1 - s2 # Set difference
2.2.9: Ejercicios
En estos ejercicios, comenzará a crear uno de los programas principales que se utilizarán durante el resto de este curso. Haga su trabajo en el archivo Work/report.py.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
Ejercicio 2.4: Una lista de tuplas
El archivo Data/portfolio.csv contiene una lista de acciones en una cartera. En el ejercicio 1.30 , escribió una función portfolio_cost(filename) que leyó este archivo y realizó un cálculo simple.
Tu código debería haberse visto así:
# pcost.py
import csv
def portfolio_cost(filename):
'''Computa el costo total (shares*price) de un archivo del portfolio'''
total_cost = 0.0
with open(filename, 'rt') as f:
rows = csv.reader(f)
headers = next(rows)
for row in rows:
nshares = int(row[1])
price = float(row[2])
total_cost += nshares * price
return total_cost
Usando este código como una guía aproximada, cree un nuevo archivo report.py. En ese archivo, defina una función read_portfolio(filename) que abra un archivo de cartera determinado y lo lea en una lista de tuplas. Para hacer esto, va a realizar algunas modificaciones menores al código anterior.
Primero, en lugar de definir total_cost = 0, creará una variable que inicialmente se establece en una lista vacía. Por ejemplo:
portfolio = []
A continuación, en lugar de sumar el costo total, convertirá cada fila en una tupla exactamente como lo hizo en el último ejercicio y la agregará a esta lista. Por ejemplo:
for row in rows:
holding = (row[0], int(row[1]), float(row[2]))
portfolio.append(holding)
Finalmente, devolverá el portfolio en una lista.
Experimente con su función de forma interactiva (solo un recordatorio de que para hacer esto, primero debe ejecutar el report.pyprograma en el intérprete):
Sugerencia: Haga uso de -i al ejecutar el archivo en la terminal, e.g. $ python -i archivo.py
>>> portfolio = read_portfolio('Data/portfolio.csv')
>>> portfolio
[('AA', 100, 32.2), ('IBM', 50, 91.1), ('CAT', 150, 83.44), ('MSFT', 200, 51.23),
('GE', 95, 40.37), ('MSFT', 50, 65.1), ('IBM', 100, 70.44)]
>>>
>>> portfolio[0]
('AA', 100, 32.2)
>>> portfolio[1]
('IBM', 50, 91.1)
>>> portfolio[1][1]
50
>>> total = 0.0
>>> for s in portfolio:
total += s[1] * s[2]
>>> print(total)
44671.15
>>>
Esta lista de tuplas que ha creado es muy similar a una matriz 2-D. Por ejemplo, puede acceder a una columna y una fila específicas mediante una búsqueda como portfolio[row][column] dónde row y column son números enteros.
Dicho esto, también puede escribir el último ciclo for usando una declaración como esta:
>>> total = 0.0
>>> for name, shares, price in portfolio:
total += shares*price
>>> print(total)
44671.15
>>>
Ejercicio 2.5: Lista de diccionarios
Tome la función que escribió en el ejercicio 2.4 y modifíquela para representar cada acción de la cartera con un diccionario en lugar de una tupla. En este diccionario, use los nombres de campo de "nombre", "acciones" y "precio" para representar las diferentes columnas en el archivo de entrada.
Experimente con esta nueva función de la misma manera que lo hizo en el ejercicio 2.4.
>>> portfolio = read_portfolio('Data/portfolio.csv')
>>> portfolio
[{'name': 'AA', 'shares': 100, 'price': 32.2}, {'name': 'IBM', 'shares': 50, 'price': 91.1},
{'name': 'CAT', 'shares': 150, 'price': 83.44}, {'name': 'MSFT', 'shares': 200, 'price': 51.23},
{'name': 'GE', 'shares': 95, 'price': 40.37}, {'name': 'MSFT', 'shares': 50, 'price': 65.1},
{'name': 'IBM', 'shares': 100, 'price': 70.44}]
>>> portfolio[0]
{'name': 'AA', 'shares': 100, 'price': 32.2}
>>> portfolio[1]
{'name': 'IBM', 'shares': 50, 'price': 91.1}
>>> portfolio[1]['shares']
50
>>> total = 0.0
>>> for s in portfolio:
total += s['shares']*s['price']
>>> print(total)
44671.15
>>>
Aquí, notará que se accede a los diferentes campos para cada entrada mediante nombres de clave en lugar de números de columna numéricos. Esto se prefiere a menudo porque el código resultante es más fácil de leer más tarde.
Ver diccionarios y listas de gran tamaño puede resultar complicado. Para limpiar la salida para la depuración, considere usar la función pprint.
>>> from pprint import pprint
>>> pprint(portfolio)
[{'name': 'AA', 'price': 32.2, 'shares': 100},
{'name': 'IBM', 'price': 91.1, 'shares': 50},
{'name': 'CAT', 'price': 83.44, 'shares': 150},
{'name': 'MSFT', 'price': 51.23, 'shares': 200},
{'name': 'GE', 'price': 40.37, 'shares': 95},
{'name': 'MSFT', 'price': 65.1, 'shares': 50},
{'name': 'IBM', 'price': 70.44, 'shares': 100}]
>>>
Ejercicio 2.6: Diccionarios como contenedor
Un diccionario es una forma útil de realizar un seguimiento de los elementos en los que desea buscar elementos utilizando un índice que no sea un número entero. En el shell de Python, intente jugar con un diccionario:
>>> prices = { }
>>> prices['IBM'] = 92.45
>>> prices['MSFT'] = 45.12
>>> prices
... look at the result ...
>>> prices['IBM']
92.45
>>> prices['AAPL']
... look at the result ...
>>> 'AAPL' in prices
False
>>>
El archivo Data/prices.csv contiene una serie de líneas con precios de acciones. El archivo se parece a esto:
"AA",9.22
"AXP",24.85
"BA",44.85
"BAC",11.27
"C",3.72
...
Escriba una función read_prices(filename)que lea un conjunto de precios como este en un diccionario donde las claves del diccionario son los nombres de las acciones y los valores en el diccionario son los precios de las acciones.
Para hacer esto, comience con un diccionario vacío y comience a insertar valores en él tal como lo hizo anteriormente. Sin embargo, ahora está leyendo los valores de un archivo.
Usaremos esta estructura de datos para buscar rápidamente el precio de un nombre de acción determinado.
Algunos pequeños consejos que necesitará para esta parte. Primero, asegúrese de usar el csvmódulo tal como lo hizo antes, no es necesario reinventar la rueda aquí.
>>> import csv
>>> f = open('Data/prices.csv', 'r')
>>> rows = csv.reader(f)
>>> for row in rows:
print(row)
['AA', '9.22']
['AXP', '24.85']
...
[]
>>>
La otra pequeña complicación es que el Data/prices.csvarchivo puede tener algunas líneas en blanco. Observe cómo la última fila de datos de arriba es una lista vacía, lo que significa que no había datos presentes en esa línea.
Existe la posibilidad de que esto provoque la muerte de su programa con una excepción. Utilice las declaraciones tryy exceptpara detectar esto según corresponda. Pensamiento: ¿sería mejor protegerse contra datos incorrectos con una ifdeclaración -en su lugar?
Una vez que haya escrito su función read_prices(), pruébela de forma interactiva para asegurarse de que funcione:
>>> prices = read_prices('Data/prices.csv')
>>> prices['IBM']
106.28
>>> prices['MSFT']
20.89
>>>
La otra pequeña complicación es que el archivo Data/prices.csv puede tener algunas líneas en blanco. Observe cómo la última fila de datos de arriba es una lista vacía, lo que significa que no había datos presentes en esa línea.
Existe la posibilidad de que esto provoque la muerte de su programa con una excepción. Utilice las declaraciones tryy exceptpara detectar esto según corresponda. Pensamiento: ¿sería mejor protegerse contra datos incorrectos con una ifdeclaración -en su lugar?
Una vez que haya escrito su función read_prices(), pruébela de forma interactiva para asegurarse de que funcione:
>>> prices = read_prices('Data/prices.csv')
>>> prices['IBM']
106.28
>>> prices['MSFT']
20.89
>>>
Ejercicio 2.7: Descubra se puede jubilar
Complete este trabajo agregando algunas declaraciones adicionales a su programa report.py que calculen ganancias / pérdidas. Estas declaraciones deben tomar la lista de acciones del ejercicio 2.5 y el diccionario de precios del ejercicio 2.6 y calcular el valor actual de la cartera junto con la ganancia / pérdida.
2.3 Salida formateada
Esta sección es una pequeña digresión, pero cuando trabaja con datos, a menudo desea producir resultados estructurados (tablas, etc.). Por ejemplo:
Name Shares Price
---------- ---------- -----------
AA 100 32.20
IBM 50 91.10
CAT 150 83.44
MSFT 200 51.23
GE 95 40.37
MSFT 50 65.10
IBM 100 70.44
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.3.1: Formateo de cadena
Una forma de formatear cadenas en Python 3.6+ es con f-strings.
>>> name = 'IBM'
>>> shares = 100
>>> price = 91.1
>>> f'{name:>10s} {shares:>10d} {price:>10.2f}'
' IBM 100 91.10'
>>>
La pieza {expression:format} se reemplaza.
Se usa comúnmente con print.
print(f'{name:>10s} {shares:>10d} {price:>10.2f}')
2.3.2: Códigos de formato
Códigos de formato (después de que el : interior de la {}) son similares a C printf(). Los códigos comunes incluyen:
d Decimal integer
b Binary integer
x Hexadecimal integer
f Float as [-]m.dddddd
e Float as [-]m.dddddde+-xx
g Float, but selective use of E notation
s String
c Character (from integer)
Los modificadores comunes ajustan el ancho del campo y la precisión decimal. Esta es una lista parcial:
:>10d Integer right aligned in 10-character field
:<10d Integer left aligned in 10-character field
:^10d Integer centered in 10-character field
:0.2f Float with 2 digit precision
2.3.3: Formateo de diccionarios
Puede utilizar el format_map()método para aplicar formato de cadena a un diccionario de valores:
>>> s = {
'name': 'IBM',
'shares': 100,
'price': 91.1
}
>>> '{name:>10s} {shares:10d} {price:10.2f}'.format_map(s)
' IBM 100 91.10'
>>>
Utiliza los mismos códigos que f-stringspero toma los valores del diccionario suministrado.
2.3.4: El método format()
Existe un método format()que puede aplicar formato a argumentos o argumentos de palabras clave.
>>> '{name:>10s} {shares:10d} {price:10.2f}'.format(name='IBM', shares=100, price=91.1)
' IBM 100 91.10'
>>> '{:10s} {:10d} {:10.2f}'.format('IBM', 100, 91.1)
' IBM 100 91.10'
>>>
Francamente, format()es un poco prolijo. Prefiero las cuerdas f.
2.3.5: Formateo al estilo C
También puede utilizar el operador de formato %.
>>> 'The value is %d' % 3
'The value is 3'
>>> '%5d %-5d %10d' % (3,4,5)
' 3 4 5'
>>> '%0.2f' % (3.1415926,)
'3.14'
Esto requiere un solo elemento o una tupla a la derecha. Códigos de formato son el modelo de la C printf() también.
Nota: Este es el único formato disponible en cadenas de bytes.
>>> b'%s has %n messages' % (b'Dave', 37)
b'Dave has 37 messages'
>>>
2.3.6: Ejercicios
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
Ejercicio 2.8: Como formatear numeros
Un problema común al imprimir números es especificar el número de decimales. Una forma de solucionar este problema es usar f-strings. Prueba estos ejemplos:
>>> value = 42863.1
>>> print(value)
42863.1
>>> print(f'{value:0.4f}')
42863.1000
>>> print(f'{value:>16.2f}')
42863.10
>>> print(f'{value:<16.2f}')
42863.10
>>> print(f'{value:*>16,.2f}')
*******42,863.10
>>>
La documentación completa sobre los códigos de formato utilizados para las cadenas f se puede encontrar aquí . El formateo también se realiza a veces utilizando el operador % de cadenas.
>>> print('%0.4f' % value)
42863.1000
>>> print('%16.2f' % value)
42863.10
>>>
La documentación sobre varios códigos utilizados con %se puede encontrar aquí.
Aunque se usa comúnmente con print, el formato de cadena no está ligado a la impresión. Si desea guardar una cadena formateada. Simplemente asígnelo a una variable.
>>> f = '%0.4f' % value
>>> f
'42863.1000'
>>>
Ejercicio 2.9: Coleccionando data
En el ejercicio 2.7, escribió un programa llamado report.pyque calculó la ganancia / pérdida de una cartera de acciones. En este ejercicio, comenzará a modificarlo para producir una tabla como esta:
Name Shares Price Change
---------- ---------- ---------- ----------
AA 100 9.22 -22.98
IBM 50 106.28 15.18
CAT 150 35.46 -47.98
MSFT 200 20.89 -30.34
GE 95 13.48 -26.89
MSFT 50 20.89 -44.21
IBM 100 106.28 35.84
En este informe, "Precio" es el precio actual de la acción de la acción y "Cambio" es el cambio en el precio de la acción desde el precio de compra inicial.
Para generar el informe anterior, primero querrá recopilar todos los datos que se muestran en la tabla. Escriba una función make_report() que tome una lista de existencias y un diccionario de precios como entrada y devuelva una lista de tuplas que contenga las filas de la tabla anterior.
Agregue esta función a su archivo report.py. Así es como debería funcionar si lo prueba de forma interactiva:
>>> portfolio = read_portfolio('Data/portfolio.csv')
>>> prices = read_prices('Data/prices.csv')
>>> report = make_report(portfolio, prices)
>>> for r in report:
print(r)
('AA', 100, 9.22, -22.980000000000004)
('IBM', 50, 106.28, 15.180000000000007)
('CAT', 150, 35.46, -47.98)
('MSFT', 200, 20.89, -30.339999999999996)
('GE', 95, 13.48, -26.889999999999997)
...
>>>
Ejercicio 2.10: Imprimiendo una tabla formateada
Rehaga el bucle for del ejercicio 2.9, pero cambie la instrucción print para formatear las tuplas.
>>> for r in report:
print('%10s %10d %10.2f %10.2f' % r)
AA 100 9.22 -22.98
IBM 50 106.28 15.18
CAT 150 35.46 -47.98
MSFT 200 20.89 -30.34
...
>>>
También puede expandir los valores y usar f-strings. Por ejemplo:
>>> for name, shares, price, change in report:
print(f'{name:>10s} {shares:>10d} {price:>10.2f} {change:>10.2f}')
AA 100 9.22 -22.98
IBM 50 106.28 15.18
CAT 150 35.46 -47.98
MSFT 200 20.89 -30.34
...
>>>
Tome las declaraciones anteriores y agréguelas a su report.pyprograma. Haga que su programa tome la salida de la función make_report() e imprima una tabla bien formateada como se muestra.
Ejercicio 2.11: Agregando algunos encabezados
Suponga que tiene una tupla de nombres de encabezado como este:
headers = ('Name', 'Shares', 'Price', 'Change')
Agregue código a su programa que toma la tupla de encabezados anterior y crea una cadena donde cada nombre de encabezado está alineado a la derecha en un campo de 10 caracteres de ancho y cada campo está separado por un solo espacio.
' Name Shares Price Change'
Escriba código que tome los encabezados y cree la cadena de separación entre los encabezados y los datos que siguen. Esta cadena es solo un grupo de caracteres "-" debajo de cada nombre de campo. Por ejemplo:
'---------- ---------- ---------- -----------'
Cuando haya terminado, su programa debería producir la tabla que se muestra en la parte superior de este ejercicio.
Name Shares Price Change
---------- ---------- ---------- ----------
AA 100 9.22 -22.98
IBM 50 106.28 15.18
CAT 150 35.46 -47.98
MSFT 200 20.89 -30.34
GE 95 13.48 -26.89
MSFT 50 20.89 -44.21
IBM 100 106.28 35.84
Ejercicio 2.12: Un reto
¿Cómo modificaría su código para que el precio incluya el símbolo de moneda ($) y la salida se vea así:
Name Shares Price Change
---------- ---------- ---------- ----------
AA 100 $9.22 -22.98
IBM 50 $106.28 15.18
CAT 150 $35.46 -47.98
MSFT 200 $20.89 -30.34
GE 95 $13.48 -26.89
MSFT 50 $20.89 -44.21
IBM 100 $106.28 35.84
2.4 Secuencias
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.4.1: Tipos de secuencias
Python tiene tres tipos de datos de secuencia .
- Cuerda:
'Hello'. Una cadena es una secuencia de caracteres. - Lista:
[1, 4, 5]. - Tupla:
('GOOG', 100, 490.1).
Todas las secuencias están ordenadas, indexadas por números enteros y tienen una longitud.
a = 'Hello' # String
b = [1, 4, 5] # List
c = ('GOOG', 100, 490.1) # Tuple
# Indexed order
a[0] # 'H'
b[-1] # 5
c[1] # 100
# Length of sequence
len(a) # 5
len(b) # 3
len(c) # 3
Las secuencias pueden ser replicados: s * n.
>>> a = 'Hello'
>>> a * 3
'HelloHelloHello'
>>> b = [1, 2, 3]
>>> b * 2
[1, 2, 3, 1, 2, 3]
>>>
Secuencias del mismo tipo pueden ser concatenados: s + t.
>>> a = (1, 2, 3)
>>> b = (4, 5)
>>> a + b
(1, 2, 3, 4, 5)
>>>
>>> c = [1, 5]
>>> a + c
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate tuple (not "list") to tuple
2.4.2: Cortar
Cortar significa tomar una subsecuencia de una secuencia. La sintaxis es s[start:end]. Donde starty endson los índices de la subsecuencia que desea.
a = [0,1,2,3,4,5,6,7,8]
a[2:5] # [2,3,4]
a[-5:] # [4,5,6,7,8]
a[:3] # [0,1,2]
- Índices
startyenddeben ser números enteros. - Las rebanadas no incluyen el valor final. Es como un intervalo medio abierto de matemáticas.
- Si se omiten los índices, por defecto van al principio o al final de la lista.
2.4.3: Reasignación de cortes
En las listas, los sectores se pueden reasignar y eliminar.
# Reasginación
a = [0,1,2,3,4,5,6,7,8]
a[2:4] = [10,11,12] # [0,1,10,11,12,4,5,6,7,8]
Nota: No es necesario que el segmento reasignado tenga la misma longitud.
# Remoción
a = [0,1,2,3,4,5,6,7,8]
del a[2:4] # [0,1,4,5,6,7,8]
2.4.4: Secuencia de reducciones
Existen algunas funciones comunes para reducir una secuencia a un solo valor.
>>> s = [1, 2, 3, 4]
>>> sum(s)
10
>>> min(s)
1
>>> max(s)
4
>>> t = ['Hello', 'World']
>>> max(t)
'World'
>>>
2.4.5: Iteracion sobre una secuencia
El bucle for itera sobre los elementos en una secuencia.
>>> s = [1, 4, 9, 16]
>>> for i in s:
... print(i)
...
1
4
9
16
>>>
En cada iteración del ciclo, obtienes un nuevo elemento con el que trabajar. Este nuevo valor se coloca en la variable de iteración. En este ejemplo, la variable de iteración es x:
for x in s: # `x` es una variable de iteración
...declaraciones
En cada iteración, el valor anterior de la variable de iteración se sobrescribe (si lo hubiera). Una vez finalizado el ciclo, la variable retiene el último valor.
2.4.6: La declaración break
Puede usar la breakdeclaración para salir de un ciclo antes de tiempo.
for name in namelist:
if name == 'Jake':
break
...
...
declaraciones
Cuando la break instrucción se ejecuta, sale del ciclo y pasa al siguiente statements. La declaración breaksolo se aplica al bucle más interno. Si este bucle está dentro de otro bucle, no romperá el bucle exterior.
2.4.7: La declaración continue
Para omitir un elemento y pasar al siguiente, use la continuedeclaración.
for line in lines:
if line == '\n': # Skip blank lines
continue
# More statements
...
Esto es útil cuando el elemento actual no es de interés o debe ignorarse en el procesamiento.
2.4.8: Ciclando sobre enteros
Si necesita contar, use range().
for i in range(100):
# i = 0,1,...,99
La sintaxis es range([start,] end [,step])
for i in range(100):
# i = 0,1,...,99 for j in range(10,20):
# j = 10,11,..., 19 for k in range(10,50,2):
# k = 10,12,...,48 # Note como cuenta en pasos de 2, no 1.
- El valor final nunca se incluye. Refleja el comportamiento de los cortes.
startes opcional. Por defecto0.stepes opcional. Por defecto1.range()calcula los valores según sea necesario. En realidad, no almacena una gran variedad de números.
2.4.9: La función enumerate()
La enumerate función agrega un valor de contador adicional a la iteración.
names = ['Elwood', 'Jake', 'Curtis']
for i, name in enumerate(names):
# Cicla con i = 0, name = 'Elwood'
# i = 1, name = 'Jake'
# i = 2, name = 'Curtis'
La forma general es enumerate(sequence [, start = 0]). start es opcional. Un buen ejemplo de uso enumerate() es el seguimiento de los números de línea mientras se lee un archivo:
with open(filename) as f:
for lineno, line in enumerate(f, start=1):
...
Al final, enumerate es solo un buen atajo para:
i = 0
for x in s:
statements
i += 1
Usar enumerate es escribir menos y se ejecuta un poco más rápido.
2.4.10: for y tuplas
Puede iterar con múltiples variables de iteración.
points = [
(1, 4),(10, 40),(23, 14),(5, 6),(7, 8)
]
for x, y in points:
# Cicla con x = 1, y = 4
# x = 10, y = 40
# x = 23, y = 14
# ...
Cuando se utilizan varias variables, cada tupla se descompone en un conjunto de variables de iteración. El número de variables debe coincidir con el número de elementos de cada tupla.
2.4.11: La función zip()
La zipfunción toma múltiples secuencias y crea un iterador que las combina.
columns = ['name', 'shares', 'price']
values = ['GOOG', 100, 490.1 ]
pairs = zip(columns, values)
# ('name','GOOG'), ('shares',100), ('price',490.1)
Para obtener el resultado, debes iterar. Puede utilizar varias variables para descomprimir las tuplas como se mostró anteriormente.
for column, value in pairs:
...
Un uso común de zipes crear pares clave / valor para construir diccionarios.
d = dict(zip(columns, values))
2.4.12: Ejercicios
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
Ejercicio 2.13: Contar
Pruebe algunos ejemplos básicos de conteo:
>>> for n in range(10): # Cuenta 0 ... 9
print(n, end=' ')
0 1 2 3 4 5 6 7 8 9
>>> for n in range(10,0,-1): # Cuenta 10 ... 1
print(n, end=' ')
10 9 8 7 6 5 4 3 2 1
>>> for n in range(0,10,2): # Cuenta 0, 2, ... 8
print(n, end=' ')
0 2 4 6 8
>>>
Ejercicio 2.14: Mas operaciones sobre secuencias
Experimente interactivamente con algunas de las operaciones de reducción de secuencia.
>>> data = [4, 9, 1, 25, 16, 100, 49]
>>> min(data)
1
>>> max(data)
100
>>> sum(data)
204
>>>
Intente recorrer los datos.
>>> for x in data:
print(x)
4
9
...
>>> for n, x in enumerate(data):
print(n, x)
0 4
1 9
2 1
...
>>
A veces, los principiantes usan la for instrucción, len() y range() en algún tipo de fragmento de código horrible que parece surgido de las profundidades de un programa C oxidado.
>>> for n in range(len(data)):
print(data[n])
4
9
1
...
>>>
¡No hagas eso! Leerlo no solo hace sangrar los ojos de todos, es ineficiente con la memoria y funciona mucho más lento. Simplemente use un for bucle normal si desea iterar sobre los datos. Úselo enumerate() si necesita el índice por alguna razón.
Ejercicio 2.15: Un ejemplo práctico de enumerate()
Recuerde que el archivo Data/missing.csv contiene datos para una cartera de acciones, pero tiene algunas filas con datos faltantes. Usando enumerate(), modifique su pcost.py programa para que imprima un número de línea con el mensaje de advertencia cuando encuentre una entrada incorrecta.
>>> cost = portfolio_cost('Data/missing.csv')
Row 4: Couldn't convert: ['MSFT', '', '51.23'] Row 7: Couldn't convert: ['IBM', '', '70.44']
>>>
Para hacer esto, necesitará cambiar algunas partes de su código.
...
for rowno, row in enumerate(rows, start=1):
try:
...
except ValueError:
print(f'Fila {rowno}: Mala fila: {row}')
Ejercicio 2.16: Usando la función zip()
En el archivo Data/portfolio.csv, la primera línea contiene encabezados de columna. En todo el código anterior, los hemos estado descartando.
>>> f = open('Data/portfolio.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> headers
['name', 'shares', 'price']
>>>
Sin embargo, ¿qué pasaría si pudieras usar los encabezados para algo útil? Aquí es donde la zip()función entra en escena. Primero intente esto para emparejar los encabezados del archivo con una fila de datos:
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>> list(zip(headers, row))
[ ('name', 'AA'), ('shares', '100'), ('price', '32.20') ]
>>>
Observe cómo se zip() emparejaron los encabezados de columna con los valores de columna. Hemos utilizado list() aquí para convertir el resultado en una lista para que pueda verlo. Normalmente, zip() crea un iterador que debe consumir un bucle for.
Este emparejamiento es un paso intermedio para crear un diccionario. Ahora prueba esto:
>>> record = dict(zip(headers, row))
>>> record
{'price': '32.20', 'name': 'AA', 'shares': '100'}
>>>
Esta transformación es uno de los trucos más útiles que debe conocer al procesar muchos archivos de datos. Por ejemplo, suponga que desea que el pcost.py programa funcione con varios archivos de entrada, pero sin tener en cuenta el número de columna real donde aparecen el nombre, las acciones y el precio.
Modifique la portfolio_cost() función pcost.py para que se vea así:
# pcost.py
def portfolio_cost(filename):
...
for rowno, row in enumerate(rows, start=1):
record = dict(zip(headers, row))
try:
nshares = int(record['shares'])
price = float(record['price'])
total_cost += nshares * price
except ValueError: # Esto atrapa errores de conversión a int() y float()
print(f'Fila {rowno}: Mala fila: {row}')
...
Ahora, pruebe su función en un archivo de datos completamente diferente Data/portfoliodate.csvque se ve así:
name,date,time,shares,price
"AA","6/11/2007","9:50am",100,32.20
"IBM","5/13/2007","4:20pm",50,91.10
"CAT","9/23/2006","1:30pm",150,83.44
"MSFT","5/17/2007","10:30am",200,51.23
"GE","2/1/2006","10:45am",95,40.37
"MSFT","10/31/2006","12:05pm",50,65.10
"IBM","7/9/2006","3:15pm",100,70.44
>>> portfolio_cost('Data/portfoliodate.csv')
44671.15
>>>
Si lo hizo bien, verá que su programa aún funciona a pesar de que el archivo de datos tiene un formato de columna completamente diferente al anterior. ¡Eso es genial!
El cambio realizado aquí es sutil, pero significativo. En lugar de portfolio_cost()estar codificado para leer un solo formato de archivo fijo, la nueva versión lee cualquier archivo CSV y selecciona los valores de interés. Siempre que el archivo tenga las columnas requeridas, el código funcionará.
Modifique el report.pyprograma que escribió en la Sección 2.3 para que utilice la misma técnica para seleccionar encabezados de columna.
Intente ejecutar el report.pyprograma en el Data/portfoliodate.csvarchivo y vea que produce la misma respuesta que antes.
Ejercicio 2.17: Invirtiendo un diccionario
Un diccionario asigna claves a valores. Por ejemplo, un diccionario de precios de acciones.
>>> prices = {
'GOOG': 490.1,
'AA': 23.45,
'IBM': 91.1,
'MSFT': 34.23
}
>>>
Si usa el método items(), puede obtener pares (key,value):
>>> prices.items()
dict_items([('GOOG', 490.1), ('AA', 23.45), ('IBM', 91.1), ('MSFT', 34.23)])
>>>
Sin embargo, ¿qué pasaría si quisiera obtener una lista de pares (value, key)? Sugerencia: use zip().
>>> pricelist = list(zip(prices.values(),prices.keys()))
>>> pricelist
[(490.1, 'GOOG'), (23.45, 'AA'), (91.1, 'IBM'), (34.23, 'MSFT')]
>>>
¿Por qué harías esto? Por un lado, le permite realizar ciertos tipos de procesamiento de datos en los datos del diccionario.
>>> min(pricelist)
(23.45, 'AA')
>>> max(pricelist)
(490.1, 'GOOG')
>>> sorted(pricelist)
[(23.45, 'AA'), (34.23, 'MSFT'), (91.1, 'IBM'), (490.1, 'GOOG')]
>>>
Esto también ilustra una característica importante de las tuplas. Cuando se usan en comparaciones, las tuplas se comparan elemento por elemento comenzando con el primer elemento. Similar a cómo se comparan las cadenas carácter por carácter.
zip() se utiliza a menudo en situaciones como esta en las que necesita emparejar datos de diferentes lugares. Por ejemplo, emparejar los nombres de las columnas con los valores de las columnas para crear un diccionario de valores con nombre.
Tenga en cuenta que zip() no se limita a pares. Por ejemplo, puede usarlo con cualquier número de listas de entrada:
>>> a = [1, 2, 3, 4]
>>> b = ['w', 'x', 'y', 'z']
>>> c = [0.2, 0.4, 0.6, 0.8]
>>> list(zip(a, b, c))
[(1, 'w', 0.2), (2, 'x', 0.4), (3, 'y', 0.6), (4, 'z', 0.8))]
>>>
Además, tenga en cuenta que zip() se detiene una vez que se agota la secuencia de entrada más corta.
>>> a = [1, 2, 3, 4, 5, 6]
>>> b = ['x', 'y', 'z']
>>> list(zip(a,b))
[(1, 'x'), (2, 'y'), (3, 'z')]
>>>
2.5 El modulo collections
El collections módulo proporciona una serie de objetos útiles para el manejo de datos. Esta parte presenta brevemente algunas de estas características.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.5.1: Ejemplo: contando cosas
Digamos que desea tabular el total de acciones de cada acción.
portfolio = [
('GOOG', 100, 490.1),
('IBM', 50, 91.1),
('CAT', 150, 83.44),
('IBM', 100, 45.23),
('GOOG', 75, 572.45),
('AA', 50, 23.15)
]
Hay dos IBM entradas y dos GOOG entradas en esta lista. Las acciones deben combinarse de alguna manera.
2.5.2: Contadores
Solución: utilice un Counter.
from collections import Counter
total_shares = Counter()
for name, shares, price in portfolio:
total_shares[name] += shares
total_shares['IBM'] # 150
2.5.3: Ejemplo: asignaciones uno-muchos
Problema: desea asignar una clave a varios valores.
portfolio = [
('GOOG', 100, 490.1),
('IBM', 50, 91.1),
('CAT', 150, 83.44),
('IBM', 100, 45.23),
('GOOG', 75, 572.45),
('AA', 50, 23.15)
]
Como en el ejemplo anterior, la clave IBMdebería tener dos tuplas diferentes en su lugar.
Solución: utilice un defaultdict.
from collections import defaultdict
holdings = defaultdict(list)
for name, shares, price in portfolio:
holdings[name].append((shares, price))
holdings['IBM'] # [ (50, 91.1), (100, 45.23) ]
El defaultdictasegura que cada vez que acceda a una clave obtenga un valor predeterminado.
2.5.4: Ejemplo: un historial
Problema: queremos un historial de las últimas N cosas. Solución: utilice un deque.
from collections import deque
history = deque(maxlen=N)
with open(filename) as f:
for line in f:
history.append(line)
...
2.5.5: Ejercicios
El collectionsmódulo puede ser uno de los módulos de biblioteca más útiles para tratar tipos de problemas de manejo de datos con fines especiales, como la tabulación y la indexación.
En este ejercicio, veremos algunos ejemplos simples. Comience ejecutando su report.py programa para que tenga la cartera de acciones cargada en el modo interactivo.
bash % python3 -i report.py
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.18: Tabulación con contadores
Suponga que desea tabular el número total de acciones de cada acción. Esto es fácil de usar Counterobjetos. Intentalo:
>>> portfolio = read_portfolio('Data/portfolio.csv')
>>> from collections import Counter
>>> holdings = Counter()
>>> for s in portfolio:
holdings[s['name']] += s['shares']
>>> holdings
Counter({'MSFT': 250, 'IBM': 150, 'CAT': 150, 'AA': 100, 'GE': 95})
>>>
Observe cuidadosamente cómo las múltiples entradas para MSFTy IBMen portfoliose combinan en una sola entrada aquí.
Puede usar un contador como un diccionario para recuperar valores individuales:
>>> holdings['IBM']
150
>>> holdings['MSFT']
250
>>>
Si desea clasificar los valores, haga esto:
>>> # Get three most held stocks >>> holdings.most_common(3)
[('MSFT', 250), ('IBM', 150), ('CAT', 150)]
>>>
Tomemos otra cartera de acciones y creemos un nuevo contador:
>>> portfolio2 = read_portfolio('Data/portfolio2.csv')
>>> holdings2 = Counter()
>>> for s in portfolio2:
holdings2[s['name']] += s['shares']
>>> holdings2
Counter({'HPQ': 250, 'GE': 125, 'AA': 50, 'MSFT': 25})
>>>
Finalmente, combinemos todas las existencias haciendo una operación simple:
>>> holdings
Counter({'MSFT': 250, 'IBM': 150, 'CAT': 150, 'AA': 100, 'GE': 95})
>>> holdings2
Counter({'HPQ': 250, 'GE': 125, 'AA': 50, 'MSFT': 25})
>>> combined = holdings + holdings2
>>> combined
Counter({'MSFT': 275, 'HPQ': 250, 'GE': 220, 'AA': 150, 'IBM': 150, 'CAT': 150})
>>>
Esto es solo una pequeña muestra de lo que ofrecen los contadores. Sin embargo, si alguna vez necesita tabular valores, debería considerar usar uno.
2.5.6: Comentario: el modulo collections
El módulo collections es uno de los módulos de biblioteca más útiles de todo Python. De hecho, podríamos hacer un tutorial extenso sobre eso. Sin embargo, hacerlo ahora también sería una distracción. Por ahora, ponga collectionssu lista de lecturas a la hora de dormir para más tarde.
2.6 Comprensión de Listas
Una tarea común es procesar elementos en una lista. Esta sección presenta listas por comprensión, una poderosa herramienta para hacer precisamente eso.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.6.1: Creando nuevas listas
Una lista de comprensión crea una nueva lista aplicando una operación a cada elemento de una secuencia.
>>> a = [1, 2, 3, 4, 5]
>>> b = [2*x for x in a ]
>>> b
[2, 4, 6, 8, 10]
>>>
Otro ejemplo:
>>> names = ['Elwood', 'Jake']
>>> a = [name.lower() for name in names]
>>> a
['elwood', 'jake']
>>>
La sintaxis general es: [ <expresión> for <variable_nombre> in <secuencia> ].
2.6.2: Filtrar
También puede filtrar durante la comprensión de la lista.
>>> a = [1, -5, 4, 2, -2, 10]
>>> b = [2*x for x in a if x > 0 ]
>>> b
[2, 8, 4, 20]
>>>
2.6.3: Casos de uso
Las listas por comprensión son muy útiles. Por ejemplo, puede recopilar valores de campos de un diccionario específico:
stocknames = [s['name'] for s in stocks]
Puede realizar consultas similares a bases de datos en secuencias.
a = [s for s in stocks if s['price'] > 100 and s['shares'] > 50 ]
También puede combinar una comprensión de lista con una reducción de secuencia:
cost = sum([s['shares']*s['price'] for s in stocks])
2.6.4: Sintaxis general
[ <expresión> for <variable_nombre> in <secuencia> si <condición>]
Que significa:
result = []
for variable_name in sequence:
if condition:
result.append(expression)
2.6.5: Digresión histórica
Las listas por comprensión provienen de las matemáticas (notación del generador de conjuntos).
a = [ x * x for x in s if x > 0 ] # Python
a = { x^2 | x ∈ s, x > 0 } # Math
También se implementa en varios otros idiomas. Sin embargo, la mayoría de los programadores probablemente no estén pensando en su clase de matemáticas. Entonces, está bien verlo como un atajo de lista genial.
2.6.6: Ejercicios
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
Comience ejecutando su report.py programa para que tenga la cartera de acciones cargada en el modo interactivo.
bash % python3 -i report.py
Ejercicio 2.19: Comprension de listas
Pruebe algunas comprensiones de listas simples solo para familiarizarse con la sintaxis.
>>> nums = [1,2,3,4]
>>> squares = [ x * x for x in nums ]
>>> squares
[1, 4, 9, 16]
>>> twice = [ 2 * x for x in nums if x > 2 ]
>>> twice
[6, 8]
>>>
Observe cómo las listas por comprensión están creando una nueva lista con los datos adecuadamente transformados o filtrados.
Ejercicio 2.20: Reducciones de secuencia
Calcule el costo total de la cartera con una sola declaración de Python.
>>> portfolio = read_portfolio('Data/portfolio.csv')
>>> cost = sum([ s['shares'] * s['price'] for s in portfolio ])
>>> cost
44671.15
>>>
Después de haber hecho eso, muestre cómo puede calcular el valor actual de la cartera con un solo extracto.
>>> value = sum([ s['shares'] * prices[s['name']] for s in portfolio ])
>>> value
28686.1
>>>
Ambas operaciones anteriores son un ejemplo de reducción de mapa. La comprensión de la lista está mapeando una operación a lo largo de la lista.
>>> [ s['shares'] * s['price'] for s in portfolio ]
[3220.0000000000005, 4555.0, 12516.0, 10246.0, 3835.1499999999996, 3254.9999999999995, 7044.0]
>>>
La sum() función está realizando después una reducción en todo el resultado:
>>> sum(_)
44671.15
>>>
Con este conocimiento, ahora está listo para lanzar una nueva empresa de big data.
Ejercicio 2.21: Consulta de datos
Pruebe los siguientes ejemplos de varias consultas de datos.
Primero, una lista de todas las posiciones de la cartera con más de 100 acciones.
>>> more100 = [ s for s in portfolio if s['shares'] > 100 ]
>>> more100
[{'price': 83.44, 'name': 'CAT', 'shares': 150}, {'price': 51.23, 'name': 'MSFT', 'shares': 200}]
>>>
Todas las posiciones en cartera de acciones de MSFT e IBM.
>>> msftibm = [ s for s in portfolio if s['name'] in {'MSFT','IBM'} ]
>>> msftibm
[{'price': 91.1, 'name': 'IBM', 'shares': 50}, {'price': 51.23, 'name': 'MSFT', 'shares': 200},
{'price': 65.1, 'name': 'MSFT', 'shares': 50}, {'price': 70.44, 'name': 'IBM', 'shares': 100}]
>>>
Una lista de todas las tenencias de la cartera que cuestan más de $10000.
>>> cost10k = [ s for s in portfolio if s['shares'] * s['price'] > 10000 ]
>>> cost10k
[{'price': 83.44, 'name': 'CAT', 'shares': 150}, {'price': 51.23, 'name': 'MSFT', 'shares': 200}]
>>>
Ejercicio 2.22: Extracción de datos
Mostrar cómo se podría construir una lista de tuplas (name, shares), donde name y sharesson tomados de portfolio.
>>> name_shares =[ (s['name'], s['shares']) for s in portfolio ]
>>> name_shares
[('AA', 100), ('IBM', 50), ('CAT', 150), ('MSFT', 200), ('GE', 95), ('MSFT', 50), ('IBM', 100)]
>>>
Si cambia los corchetes ( [, ]) por llaves ( {, }), obtendrá algo conocido como comprensión de conjuntos. Esto le brinda valores únicos o distintos.
Por ejemplo, esto determina el conjunto de nombres de acciones únicos que aparecen en portfolio:
>>> names = { s['name'] for s in portfolio }
>>> names
{ 'AA', 'GE', 'IBM', 'MSFT', 'CAT'] }
>>>
Si especifica key:valuepares, puede crear un diccionario. Por ejemplo, cree un diccionario que asigne el nombre de una acción al número total de acciones que posee.
>>> holdings = { name: 0 for name in names }
>>> holdings
{'AA': 0, 'GE': 0, 'IBM': 0, 'MSFT': 0, 'CAT': 0}
>>>
Esta última característica se conoce como comprensión de diccionario . Vamos a tabular:
>>> for s in portfolio:
holdings[s['name']] += s['shares']
>>> holdings
{ 'AA': 100, 'GE': 95, 'IBM': 150, 'MSFT':250, 'CAT': 150 }
>>>
Pruebe este ejemplo que filtra el diccionario prices solo a los nombres que aparecen en la cartera:
>>> portfolio_prices = { name: prices[name] for name in names }
>>> portfolio_prices
{'AA': 9.22, 'GE': 13.48, 'IBM': 106.28, 'MSFT': 20.89, 'CAT': 35.46}
>>>
Ejercicio 2.23: Extracción de datos desde archivos CSV
Saber cómo utilizar varias combinaciones de comprensiones de listas, conjuntos y diccionarios puede resultar útil en diversas formas de procesamiento de datos. A continuación, se muestra un ejemplo que muestra cómo extraer columnas seleccionadas de un archivo CSV.
Primero, lea una fila de información de encabezado de un archivo CSV:
>>> import csv
>>> f = open('Data/portfoliodate.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> headers
['name', 'date', 'time', 'shares', 'price']
>>>
A continuación, defina una variable que enumere las columnas que realmente le interesan:
>>> select = ['name', 'shares', 'price']
>>>
Ahora, ubique los índices de las columnas anteriores en el archivo CSV de origen:
>>> indices = [ headers.index(colname) for colname in select ]
>>> indices
[0, 3, 4]
>>>
Finalmente, lea una fila de datos y conviértala en un diccionario usando una comprensión de diccionario:
>>> row = next(rows)
>>> record = { colname: row[index] for colname, index in zip(select, indices) } # dict-comprehension >>> record
{'price': '32.20', 'name': 'AA', 'shares': '100'}
>>>
Si se siente cómodo con lo que acaba de suceder, lea el resto del archivo:
>>> portfolio = [ { colname: row[index] for colname, index in zip(select, indices) } for row in rows ]
>>> portfolio
[{'price': '91.10', 'name': 'IBM', 'shares': '50'}, {'price': '83.44', 'name': 'CAT', 'shares': '150'},
{'price': '51.23', 'name': 'MSFT', 'shares': '200'}, {'price': '40.37', 'name': 'GE', 'shares': '95'},
{'price': '65.10', 'name': 'MSFT', 'shares': '50'}, {'price': '70.44', 'name': 'IBM', 'shares': '100'}]
>>>
Vaya, acabas de reducir gran parte de la read_portfolio() función a una sola declaración.
Comentario
Las listas por comprensión se utilizan comúnmente en Python como un medio eficaz para transformar, filtrar o recopilar datos. Debido a la sintaxis, no querrá exagerar; intente que la comprensión de cada lista sea lo más simple posible. Está bien dividir las cosas en varios pasos. Por ejemplo, no está claro si le gustaría dar ese último ejemplo a sus compañeros de trabajo desprevenidos.
Dicho esto, saber cómo manipular datos rápidamente es una habilidad increíblemente útil. Existen numerosas situaciones en las que es posible que deba resolver algún tipo de problema único que involucre la importación, exportación, extracción de datos, etc. Convertirse en un maestro gurú de la comprensión de listas puede reducir sustancialmente el tiempo dedicado a idear una solución. Además, no se olvide del collections módulo.
2.7 Objetos
Esta sección presenta más detalles sobre el modelo de objetos internos de Python y analiza algunos asuntos relacionados con la administración de memoria, la copia y la verificación de tipos.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
2.7.1: Asignacion
Muchas operaciones en Python están relacionadas con la asignación o el almacenamiento de valores.
a = value # Asignación a una variable
s[n] = value # Asignación a una lista
s.append(value) # Agregando a una lista
d['key'] = value # Agregando a un diccionario
Una advertencia: las operaciones de asignación nunca hacen una copia del valor asignado. Todas las asignaciones son simplemente copias de referencia (o copias de puntero si lo prefiere).
2.7.2: Ejemplo de asignacion
Considere este fragmento de código.
a = [1,2,3]
b = a
c = [a,b]
Una imagen de las operaciones de memoria subyacentes. En este ejemplo, solo hay un objeto de lista [1,2,3], pero hay cuatro referencias diferentes a él.
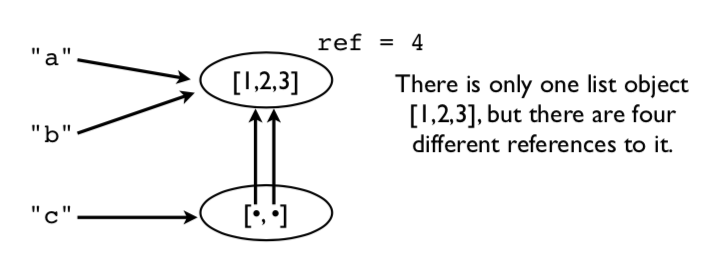
Esto significa que la modificación de un valor afecta a todas las referencias.
>>> a.append(999)
>>> a
[1,2,3,999]
>>> b
[1,2,3,999]
>>> c
[[1,2,3,999], [1,2,3,999]]
>>>
Observe cómo un cambio en la lista original aparece en todas partes (¡ay!). Esto se debe a que nunca se hicieron copias. Todo apunta a lo mismo.
2.7.3: Reasignacion de valores
La reasignación de un valor nunca sobrescribe la memoria utilizada por el valor anterior.
a = [1,2,3]
b = a
a = [4,5,6]
print(a) # [4, 5, 6]
print(b) # [1, 2, 3] Tiene el valor original
Recuerde: las variables son nombres, no ubicaciones de memoria.
2.7.4: Algunos peligros
Si no sabe acerca de este intercambio, se disparará en el pie en algún momento. Escenario típico. Modifica algunos datos pensando que es su propia copia privada y accidentalmente corrompe algunos datos en alguna otra parte del programa.
Comentario: Esta es una de las razones por las que los tipos de datos primitivos (int, float, string) son inmutables (solo lectura).
2.7.5: Identidad y referencia
Utilice el operador is para comprobar si dos valores son exactamente el mismo objeto.
>>> a = [1,2,3]
>>> b = a
>>> a is b
True
>>>
iscompara la identidad del objeto (un número entero). La identidad se puede obtener utilizando id().
>>> id(a)
3588944
>>> id(b)
3588944
>>>
Nota: Casi siempre es mejor utilizar == para comparar objetos. El comportamiento de is suele ser inesperado:
>>> a = [1,2,3]
>>> b = a
>>> c = [1,2,3]
>>> a is b
True
>>> a is c
False
>>> a == c # hmm... ¿por qué?
True
>>>
2.7.6: Copias superficiales
Las listas y los dictados tienen métodos para copiar.
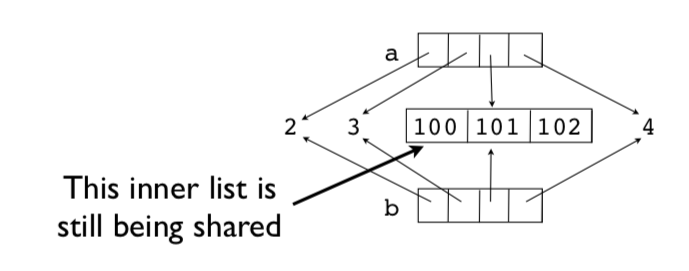
>>> a = [2,3,[100,101],4]
>>> b = list(a) # Make a copy >>> a is b
False
Es una lista nueva, pero los elementos de la lista se comparten.
>>> a[2].append(102)
>>> b[2]
[100,101,102]
>>>
>>> a[2] is b[2]
True
>>>
Por ejemplo, [100, 101, 102]se comparte la lista interna . Esto se conoce como copia superficial. Aquí tienes una foto.
2.7.8: Copias profundas
A veces es necesario hacer una copia de un objeto y todos los objetos que contiene. Puede utilizar el módulo copypara esto:
>>> a = [2,3,[100,101],4]
>>> import copy
>>> b = copy.deepcopy(a)
>>> a[2].append(102)
>>> b[2]
[100,101]
>>> a[2] is b[2]
False
>>>
2.7.9: Nombres, valores, tipos
Los nombres de las variables no tienen tipo . Es solo un nombre. Sin embargo, los valores no tienen un tipo subyacente.
>>> a = 42
>>> b = 'Hello World'
>>> type(a)
<type 'int'>
>>> type(b)
<type 'str'>
type() te dirá qué es. El nombre del tipo se usa generalmente como una función que crea o convierte un valor a ese tipo.
2.7.10: Verificación de tipo
Cómo saber si un objeto es de un tipo específico.
if isinstance(a, list):
print('a is a list')
Comprobando uno de los muchos tipos posibles.
if isinstance(a, (list,tuple)):
print('a is a list or tuple')
Precaución: No se exceda con la verificación de tipos. Puede conducir a una complejidad de código excesiva. Por lo general, solo lo haría si al hacerlo evitaría errores comunes cometidos por otros que usan su código.
2.7.11: Todo es un objeto
Los números, cadenas, listas, funciones, excepciones, clases, instancias, etc. son todos objetos. Significa que todos los objetos que se pueden nombrar pueden pasarse como datos, colocarse en contenedores, etc., sin ninguna restricción. No hay tipos especiales de objetos. A veces se dice que todos los objetos son de "primera clase".
Un simple ejemplo:
>>> import math
>>> items = [abs, math, ValueError ]
>>> items
[<built-in function abs>,
<module 'math' (builtin)>,
<type 'exceptions.ValueError'>]
>>> items[0](-45)
45
>>> items[1].sqrt(2)
1.4142135623730951
>>> try:
x = int('not a number')
except items[2]:
print('Failed!')
Failed!
>>>
Aquí itemshay una lista que contiene una función, un módulo y una excepción. Puede utilizar directamente los elementos de la lista en lugar de los nombres originales:
items[0](-45) # abs
items[1].sqrt(2) # math
except items[2]: # ValueError
Un gran poder conlleva responsabilidad. El hecho de que pueda hacer eso no significa que deba hacerlo.
2.33: Ejercicios
En este conjunto de ejercicios, analizamos parte del poder que proviene de los objetos de primera clase.
Nota: si desea hacer esta sección online, hemos puesto a disposición un editor, consola Python y terminal Linux en repl.it. De lo contrario, tendrá que ejecutar instrucciones en su ordenador
Ejercicio 2.24: Data de primera-clase
En el archivo Data/portfolio.csv, leemos datos organizados como columnas que se ven así:
name,shares,price
"AA",100,32.20
"IBM",50,91.10
...
En el código anterior, usábamos el csvmódulo para leer el archivo, pero aún teníamos que realizar conversiones de tipo manuales. Por ejemplo:
for row in rows:
name = row[0]
shares = int(row[1])
price = float(row[2])
Este tipo de conversión también se puede realizar de una manera más inteligente utilizando algunas operaciones básicas de lista.
Haga una lista de Python que contenga los nombres de las funciones de conversión que usaría para convertir cada columna en el tipo apropiado:
>>> types = [str, int, float]
>>>
La razón por la que incluso puede crear esta lista es que todo en Python es de primera clase . Entonces, si desea tener una lista de funciones, está bien. Los elementos de la lista que ha creado son funciones para convertir un valor xen un tipo determinado (por ejemplo, str(x), int(x), float(x)).
Ahora, lea una fila de datos del archivo anterior:
>>> import csv
>>> f = open('Data/portfolio.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>>
Como se señaló, esta fila no es suficiente para hacer cálculos porque los tipos son incorrectos. Por ejemplo:
>>> row[1] * row[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't multiply sequence by non-int of type 'str' >>>
Sin embargo, tal vez los datos se puedan emparejar con los tipos que especificó en types. Por ejemplo:
>>> types[1]
<type 'int'>
>>> row[1]
'100'
>>>
Intente convertir uno de los valores:
>>> types[1](row[1]) # Same as int(row[1]) 100
>>>
Intente convertir un valor diferente:
>>> types[2](row[2]) # Same as float(row[2]) 32.2
>>>
Pruebe el cálculo con valores convertidos:
>>> types[1](row[1])*types[2](row[2])
3220.0000000000005
>>>
Comprima los tipos de columna con los campos y observe el resultado:
>>> r = list(zip(types, row))
>>> r
[(<type 'str'>, 'AA'), (<type 'int'>, '100'), (<type 'float'>,'32.20')]
>>>
Notará que esto ha emparejado una conversión de tipo con un valor. Por ejemplo, int se empareja con el valor '100'.
La lista comprimida es útil si desea realizar conversiones en todos los valores, uno tras otro. Prueba esto:
>>> converted = []
>>> for func, val in zip(types, row):
converted.append(func(val))
...
>>> converted
['AA', 100, 32.2]
>>> converted[1] * converted[2]
3220.0000000000005
>>>
Asegúrese de comprender lo que sucede en el código anterior. En el bucle, la func variable es una de las funciones de conversión de tipo (por ejemplo, str, int, etc.) y la val variable es uno de los valores como 'AA', '100'. La expresión func(val)está convirtiendo un valor (algo así como un tipo de conversión).
El código anterior se puede comprimir en una sola lista comprensiva.
>>> converted = [func(val) for func, val in zip(types, row)]
>>> converted
['AA', 100, 32.2]
>>>
Ejercicio 2.25: Creando diccionarios
¿Recuerda cómo la función dict() puede hacer fácilmente un diccionario si tiene una secuencia de nombres y valores clave? Hagamos un diccionario a partir de los encabezados de las columnas:
>>> headers
['name', 'shares', 'price']
>>> converted
['AA', 100, 32.2]
>>> dict(zip(headers, converted))
{'price': 32.2, 'name': 'AA', 'shares': 100}
>>>
Por supuesto, si está en su lista de comprensión fu, puede hacer toda la conversión en un solo paso usando un dict-comprehension:
>>> { name: func(val) for name, func, val in zip(headers, types, row) }
{'price': 32.2, 'name': 'AA', 'shares': 100}
>>>
Ejercicio 2.26: El horizonte
Con las técnicas de este ejercicio, podría escribir declaraciones que conviertan fácilmente campos de casi cualquier archivo de datos orientado a columnas en un diccionario de Python.
Solo para ilustrar, suponga que lee datos de un archivo de datos diferente como este:
>>> f = open('Data/dowstocks.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> headers
['name', 'price', 'date', 'time', 'change', 'open', 'high', 'low', 'volume']
>>> row
['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '39.67', '39.69', '39.45', '181800']
>>>
Convirtamos los campos usando un truco similar:
>>> types = [str, float, str, str, float, float, float, float, int]
>>> converted = [func(val) for func, val in zip(types, row)]
>>> record = dict(zip(headers, converted))
>>> record
{'volume': 181800, 'name': 'AA', 'price': 39.48, 'high': 39.69,
'low': 39.45, 'time': '9:36am', 'date': '6/11/2007', 'open': 39.67,
'change': -0.18}
>>> record['name']
'AA'
>>> record['price']
39.48
>>>
Extra: ¿Cómo modificaría este ejemplo para analizar adicionalmente la entrada date en una tupla como (6, 11, 2007)?
Dedique algún tiempo a reflexionar sobre lo que ha hecho en este ejercicio. Revisaremos estas ideas un poco más tarde.